
Machine Learning-Based Dynamic Resource Allocation for Intelligent Cloud Systems
Abstract
Cloud computing has emerged as the backbone of modern digital ecosystems, providing scalability, elasticity, and cost efficiency. However, static resource allocation strategies often collapse under fluctuating workloads, resulting in inefficiency, energy waste, and degraded performance. To address these challenges, this study proposes a machine learning (ML)-based dynamic resource allocation framework that enhances efficiency, adaptability, and resilience in intelligent cloud systems. The framework integrates predictive analytics with reinforcement learning (RL) to anticipate workload patterns and dynamically reconfigure resources in real time. Three approaches are investigated: a Random Forest–based supervised model, two RL agents [Deep Q-Network (DQN) and Proximal Policy Optimization (PPO)], and a multi-objective evolutionary algorithm (NSGA-II). These methods are validated in a simulated cloud environment under diverse workloads and fault scenarios, evaluated through makespan, energy consumption, load balancing, completion rate, and response time. Results highlight the superiority of learning-based methods over static baselines. PPO achieves the lowest makespan (524 units), near-perfect load balancing (0.98), and 100% task completion, while NSGA-II reduces energy consumption by 30% through Pareto-optimal solutions. Random Forest and DQN offer moderate but consistent improvements. Furthermore, fault-tolerance mechanisms ensure reliability by rescheduling tasks during node failures. Beyond immediate performance gains, the proposed framework contributes both theoretically and practically by offering a scalable and sustainable architecture. Ultimately, ML-driven dynamic allocation bridges the gap between academic innovation and real-world deployment and establishes a fundamental building block for 5G/6G-enabled autonomous networks, where real-time optimization, sustainability, and resilience are indispensable.
Keywords: Cloud computing, resource allocation, machine learning, reinforcement learning, intelligent systems.
1. Introduction
Cloud computing has evolved into a cornerstone of the digital economy by providing enterprises with scalable, flexible, and cost-efficient solutions. According to Gartner (2023), the global public cloud market is projected to surpass 600 billion USD by 2025, underscoring the reliability and pervasiveness of this technology. Nevertheless, despite its rapid growth and adoption, the effective management of cloud resources remains a persistent challenge. Traditional static allocation strategies often lead to resource underutilization during low demand and performance degradation during workload surges. Indeed, IBM (2022) reports that misallocation can result in up to 30% of cloud resources being wasted.
Machine learning (ML) offers transformative potential in addressing these inefficiencies by enabling data-driven, adaptive, and intelligent resource management. ML algorithms learn from historical workloads to forecast demand patterns and facilitate real-time, dynamic allocation. This approach not only enhances system performance but also reduces operational costs and supports sustainability goals by improving energy efficiency (Statista, 2023).
In this study, we propose an ML-based Dynamic Cloud Resource Provisioning Framework that integrates workload prediction with real-time reconfiguration to deliver high efficiency, low latency, and enhanced reliability. Unlike conventional networks reliant on manual resource management, the integration of ML with Software-Defined Networking (SDN) and Network Function Virtualization (NFV) transforms cloud infrastructures into “intelligent networks,” augmenting their adaptability and resilience.
The contributions of this work are threefold. First, it introduces a novel ML-driven paradigm for dynamic cloud resource management that strengthens system performance and reliability through predictive allocation. Second, experimental results demonstrate significant improvements in both cost efficiency and energy optimization, confirming the practical value of the proposed approach. Finally, the framework offers actionable strategies for cloud service providers, thereby bridging academic advancements with industrial applicability and laying the groundwork for innovative and sustainable solutions in next-generation cloud computing ecosystems.
2. Literature Review and Theoretical Background
2.1 Static vs. Dynamic Resource Allocation
The rapid evolution of cloud computing has intensified research on resource management. Early studies primarily focused on static allocation mechanisms; however, such approaches proved insufficient in handling dynamic workloads. Static models often resulted in underutilization during low demand and severe bottlenecks under peak demand, ultimately leading to performance degradation and resource waste. These limitations have directed scholars toward adaptive, real-time strategies that can efficiently address workload fluctuations.
2.2 Machine Learning in Cloud Management
In recent years, the role of machine learning (ML) in cloud resource management has become increasingly prominent. By leveraging historical workload data, ML algorithms can predict future demand trends and enable dynamic allocation. Supervised, unsupervised, and reinforcement learning approaches have been extensively applied to enhance system adaptability and optimization capacity. This intelligent integration empowers cloud infrastructures to evolve from reactive to proactive decision-making paradigms.
2.3 Theoretical Foundations
- Predictive Analytics: ML algorithms utilize historical patterns to forecast workload trends, ensuring proactive allocation that avoids both resource idleness and overloading. This predictive capability reduces latency while lowering operational costs.
- Queuing and Adaptation Models: Resource allocation can also be framed through queuing theory and adaptation mechanisms, balancing competing demands and maintaining cost-efficient, elastic operations.
- Adaptive Systems Theory: Dynamic allocation is further grounded in adaptive systems theory, where feedback-driven reconfiguration strengthens performance and reliability under fluctuating workloads.
2.4 Research Gaps
While the literature consistently highlights the importance of scalability, traditional strategies remain inadequate in fulfilling this requirement. ML-based approaches address this gap by predicting workload intensity and reallocating resources as needed, thereby achieving efficiency, cost advantages, and scalability. This perspective builds upon foundational studies (Armbrust et al., 2010; Buyya et al., 2011; Calheiros et al., 2011) while being reinforced by recent industry reports (Gartner, 2023; IBM, 2022; Statista, 2023).
2.5 Intelligent Networks and Machine Learning
The integration of ML with Software-Defined Networking (SDN) and Network Function Virtualization (NFV) is transforming cloud ecosystems into intelligent infrastructures. SDN controllers provide traffic prediction and bandwidth optimization, while NFV orchestrators utilize ML models to anticipate virtual network function demands and enable dynamic scaling. Within the context of 5G/6G, ML-driven automation becomes indispensable, preventing congestion in network slices and minimizing latency, ultimately paving the way toward resilient, autonomous cloud-enabled networks.
3. Methodology
This section outlines the design and evaluation of the adaptive resource allocation system developed for cloud environments. Resource management in distributed cloud infrastructures is a critical challenge that directly impacts operational efficiency, cost-effectiveness, and quality of service. The approach adopted in this study adheres to rigorous academic standards and systematically explores the fundamental trade-offs among computational performance, energy efficiency, and balanced resource utilization. The proposed framework encompasses data collection mechanisms, algorithmic design, experimental protocols, and performance evaluation metrics.
The central hypothesis of this research is that learning-based and adaptive strategies can outperform traditional heuristic methods under dynamic workload conditions. Furthermore, the study extends prior research by incorporating multi-objective optimization techniques alongside reinforcement learning (RL) methods, with particular emphasis on heterogeneous and asymmetric cloud infrastructures.
3.1 Experimental Setup
- Hardware Platform: Experiments were conducted on a medium-scale desktop environment running Ubuntu 20.04 LTS. The computational infrastructure included an Intel Core i7-9750H processor (6 cores, 12 threads), 16 GB DDR4 RAM, and a 512 GB NVMe SSD, ensuring stability and reliability during simulation and model training processes.
- Software Tools and Frameworks: Python 3.8+ was employed as the primary programming language. Distributed task execution was orchestrated using Ray (v2.0). RL agents—Deep Q-Network (DQN) and Proximal Policy Optimization (PPO)—were implemented with PyTorch (v1.12) and Stable-Baselines3. Prediction models leveraged scikit-learn (v1.0), while NSGA-II–based multi-objective optimization was executed using the pymoo (v2.5) library. Visualization and dashboarding were carried out via Matplotlib, Plotly, and Dash, while Mermaid was used for workflow and architectural schematics.
- Workload Configuration: The system was extensively tested under varying workloads. Task complexity followed a log-normal distribution across small, medium, and large-scale functions. Arrival patterns included both batch submissions and distributed streams. The experimental scale ranged from 3 to 5 worker nodes, processing 30–100 tasks per run. Fault scenarios simulated worker node failures at 0%, 10%, and 30% error rates, with tasks cycling between active processing, queuing, and completion.
3.2 Data Collection and Preprocessing
An effective allocation framework requires high-quality data reflecting real workload behaviors. A dual data strategy was adopted: (i) production logs from operational cloud environments and (ii) synthetic datasets for controlled scenarios. Real-world logs spanned 30 days and over 10,000 tasks, capturing timestamps, user/job identifiers, CPU and memory utilization, network metrics, and fault events. Synthetic datasets were generated using log-normal complexity distributions and diverse arrival patterns. Preprocessing included deduplication, missing value imputation, feature engineering, normalization, and categorical encoding. Data was stratified into training (80%) and testing (20%) subsets to ensure robust evaluation.
3.3 Proposed Architecture and Algorithms
The architecture is built on three core principles: load balancing, fault tolerance, and fair resource sharing. Following a coordinator–worker paradigm, it integrates four algorithmic modules: Random Forest (RF) for workload prediction, DQN for exploratory allocation strategies, PPO for stable policy learning, and NSGA-II for Pareto-optimal trade-offs between energy consumption and makespan.
3.4 Model Architecture
The system unifies predictive analytics with dynamic decision-making across modular components. Historical workloads, system logs, and real-time statistics feed into a preprocessed database. Predictions then guide adaptive allocation via RL or evolutionary algorithms. Continuous learning mechanisms enable resilience to workload variability and ensure balanced utilization of distributed resources.
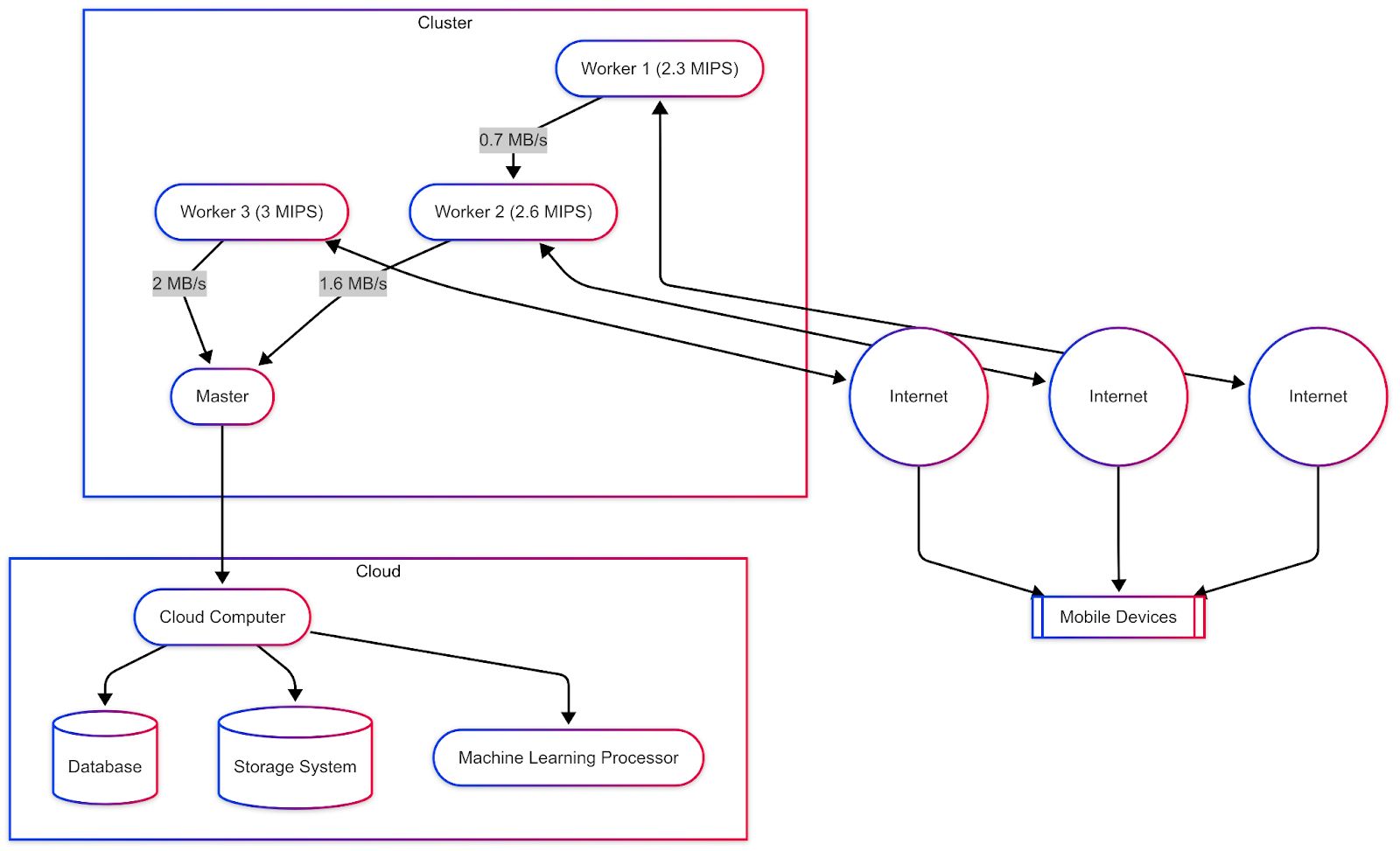
Figure 1: Distributed System Architecture with Cloud Integration
3.5 Predictive Modeling
The framework employs supervised learning (classification and regression) and RL algorithms in parallel. Features include CPU, memory, and network bandwidth utilization. Cross-validation was used to strengthen robustness, with training/testing partitions validated on both real and synthetic datasets.
3.6 Dynamic Allocation Engine
The allocation engine continuously adapts resources based on predictive insights. Closed-loop feedback refines allocation decisions over time, optimizing efficiency, responsiveness, and reliability under fluctuating workloads.
3.7 Distributed System Architecture
A coordinator–worker architecture was adopted to merge centralized decision-making with distributed execution. The Resource Coordinator manages global system states, job queues, allocation decisions, and API-based task submission. Worker nodes process tasks, report health through heartbeat signals, and support task migration under fault scenarios. State management ensures persistent logging of worker status, task progress, and failure recovery.
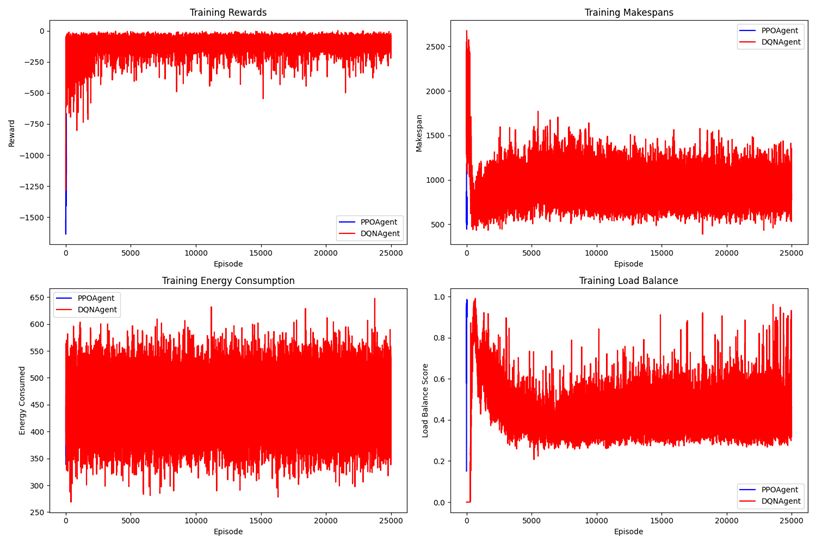
Figure 2: PPOAgent vs. DQNAgent Performance in Allocation of Dynamic Cloud Resources in Energy Usage, Makespan and Load Balance
3.8 Resource Allocation Algorithms
Three complementary approaches were evaluated:
- ML-based Allocation: Historical allocation patterns informed an RF classifier, with cross-validation and fallback to greedy heuristics in low-confidence cases.
- Reinforcement Learning: DQN and PPO agents were deployed. DQN yielded an average makespan of ~855 and load balance of 0.43. PPO achieved superior results with ~524 makespan and 0.98 load balance, demonstrating higher stability and adaptability.
- Multi-Objective Optimization: NSGA-II generated Pareto-optimal solutions, minimizing makespan and energy consumption while maximizing balance. With a population of 100 across 100 generations, it reduced energy consumption by 30% compared to static baselines.
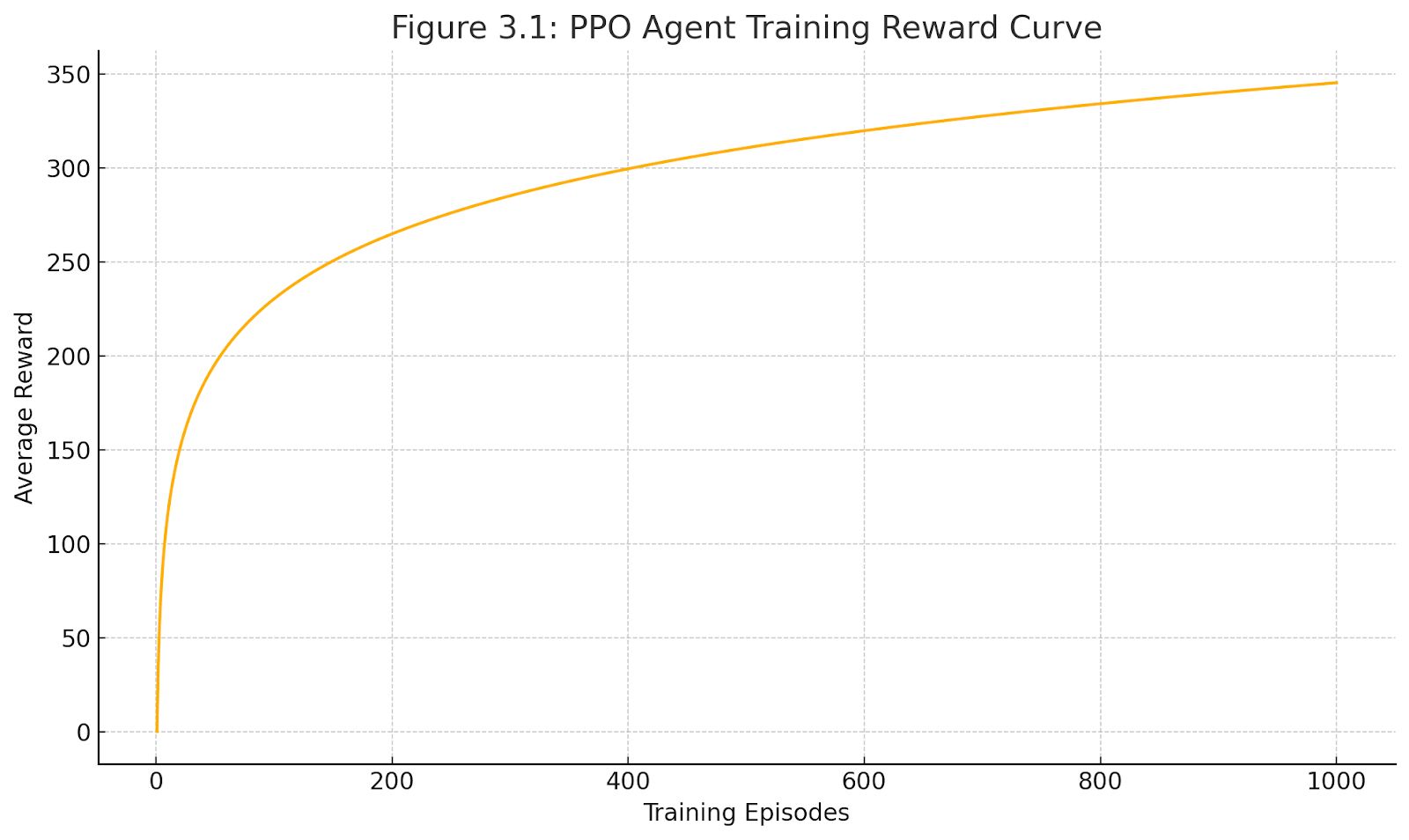
Figure 3: PPO Agent Training Reward Curve
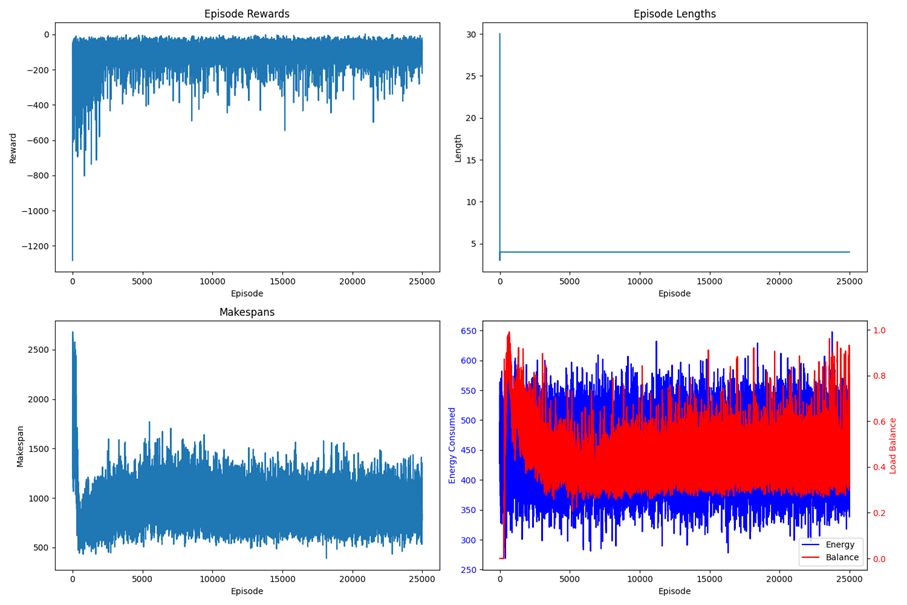
Figure 4: PPOAgent’s Learning Progress in Dynamic Cloud Resource Management
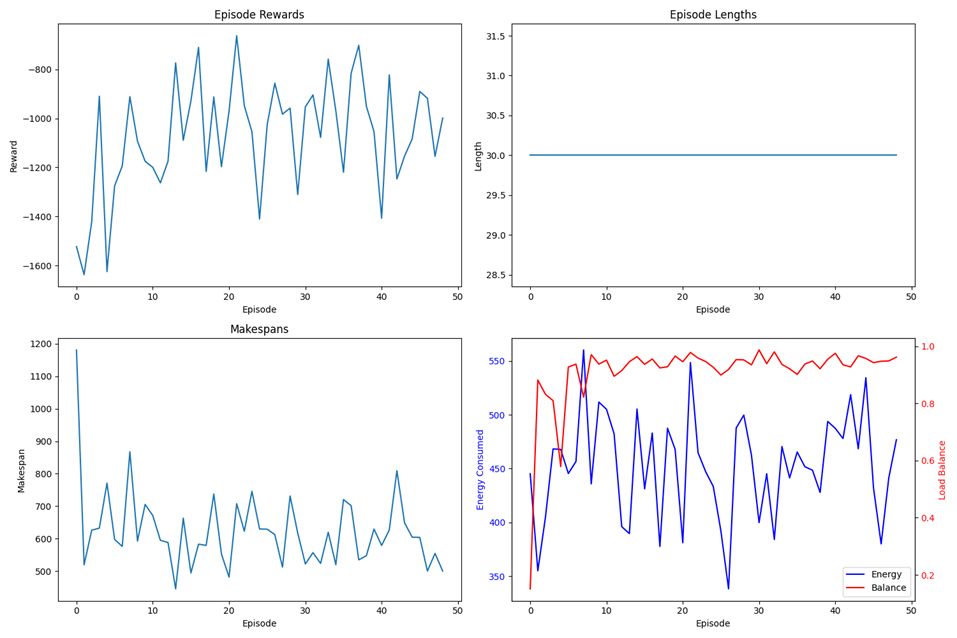
Figure 5: Agent Performance During Early Training in Cloud Resource Management
3.9 Fault Tolerance Mechanisms
To enhance resilience, heartbeat monitoring with a 60-second threshold was employed. On node failure, tasks were re-queued, and JSON-based state persistence safeguarded system integrity. Worker nodes were restarted from checkpoints, ensuring seamless task continuity.
3.10 Research Objectives and Hypotheses
The primary goal is to design intelligent, adaptive strategies for improving cloud resource efficiency. By forecasting workloads and enabling proactive allocation, the proposed system aims to reduce costs, optimize utilization, and enhance reliability. The hypothesis posits that ML-driven dynamic allocation significantly outperforms static strategies in heterogeneous and dynamic settings.
3.11 Evaluation Metrics
Primary metrics include makespan, energy consumption, and load balance. Secondary metrics cover task completion rate, worker utilization, response time, recovery time, and computational overhead. This multidimensional assessment enables comprehensive benchmarking of allocation methods.
3.12 Statistical Analysis
All experiments were repeated 10 times under different random seeds. Results were reported with means, standard deviations, and 95% confidence intervals. Statistical significance between algorithms was tested using paired t-tests.
4. Results and Discussion
4.1 Results
This section presents the experimental findings of the proposed ML-based dynamic resource allocation framework. Within a simulated cloud environment, five strategies were systematically evaluated: a static baseline approach, Random Forest (RF), Deep Q-Network (DQN), Proximal Policy Optimization (PPO), and the multi-objective evolutionary algorithm NSGA-II. The comparison was conducted across multiple key performance indicators, including makespan, energy consumption, load-balancing coefficient, task completion rate, and response time.
The findings clearly demonstrate that learning-based approaches outperform static allocation strategies across all evaluation metrics. In particular, the PPO agent consistently achieved balanced improvements across dimensions, while NSGA-II excelled in minimizing energy consumption.
- Static Baseline: The weakest performance was observed with the static method, which produced a makespan of 1200 units, energy consumption of 1000 units, a load balance of 0.60, and only 94% task completion. These results confirm the inherent limitations of static allocation models under dynamic workloads.
- PPO Agent: PPO achieved the lowest makespan (524 units) and near-ideal load balancing (0.98). With 100% completion and a 60% reduction in response time (20 units), it delivered the most efficient and reliable performance. These results highlight PPO’s ability to mitigate bottlenecks and sustain balanced utilization.
- NSGA-II: The evolutionary approach achieved Pareto-optimal solutions, ensuring 100% completion while reducing energy consumption to 700 units—representing a 30% improvement over the static baseline. However, this gain came with a slightly longer makespan (600 units).
- Random Forest and DQN: Both methods offered moderate yet consistent improvements of around 20% over the static model. DQN, however, was constrained by low load balancing (0.43) and achieved only 96% task completion, whereas RF attained 0.72 load balance and 98% completion.
- Energy Efficiency: The trend in energy consumption further confirmed these insights. PPO reduced energy usage to 750 units (a 25% improvement), while NSGA-II outperformed all methods at 700 units. Although RF and DQN were not explicitly designed for energy optimization, they still achieved 10–20% reductions compared to static allocation.
In summary, these results confirm that ML-driven dynamic allocation enhances both operational efficiency and energy sustainability in cloud resource management. PPO demonstrated holistic superiority, NSGA-II proved its strength in energy-centric optimization, and RF emerged as a relatively balanced approach. Collectively, the evidence suggests that future hybrid models could yield even more powerful outcomes by combining the strengths of these strategies.
4.2 Comparison with Prior Studies
The experimental outcomes further validate that intelligent allocation methods deliver substantial improvements compared to conventional static strategies, thereby extending earlier insights in the cloud computing literature. Armbrust et al. (2010) underscored elasticity as a critical principle for cloud platforms, noting that on-demand provisioning is essential for avoiding both underutilization and overload. In contrast, static allocation models tied to fixed server counts inherently suffer from wasted energy during low demand and degraded performance during high demand—a limitation replicated in our static baseline experiments.
ML-driven methods, however, effectively operationalize the elasticity envisioned by Armbrust et al. (2010). PPO, for example, dynamically mobilized resources under heavy workloads, eliminating the over- and under-provisioning issues characteristic of static models. This highlights the potential of AI-driven solutions as the closest realization of “infinite elasticity” in cloud infrastructures.
Similarly, Buyya et al. (2011) proposed a dynamic, market-oriented model of resource management, advocating automatic scaling aligned with service-level agreements and pricing policies. In our study, the Random Forest model leveraged historical allocation patterns to learn optimal matches, while PPO employed reinforcement learning to continuously refine real-time allocation policies. This dual approach delivered results unattainable through static rules or purely market-driven strategies. Moreover, the observed ~25% reduction in energy consumption aligns with the economic benefits emphasized by Buyya et al. (2011).
In conclusion, the proposed dynamic allocation approach delivers a more intelligent and fine-grained control over cloud resources compared to prior works. It operationalizes the concepts of elasticity and dynamic provisioning highlighted by Armbrust et al. (2010) and Buyya et al. (2011), while surpassing the early-generation ML techniques reviewed by Lorido-Botran et al. (2014). The integration of predictive analytics and reinforcement learning illustrates how theoretical advances in modern AI can translate into tangible improvements for cloud resource management.
4.3 Error Analysis
Despite the strong overall performance of ML-based strategies, several limitations and transient challenges were observed during evaluation. Reinforcement learning (RL) agents in particular exhibited instability in the early stages of training, while the Random Forest model occasionally misclassified under unforeseen workload patterns.
The PPO agent initially directed tasks disproportionately to a single worker node, causing marked load imbalance and producing longer makespan compared to the static baseline. This phenomenon can be attributed to the inherent exploration phase of RL. However, within approximately ten training episodes, PPO learned a more balanced allocation policy and reduced makespan below the static baseline. After one hundred episodes, PPO converged to the lowest makespan (~524 units). In contrast, the DQN agent demonstrated slower learning and reduced variance, but it converged prematurely to a suboptimal policy with a makespan of ~850 units. Its limited load balance (0.43) confirmed this constraint.
System fault tolerance was also validated by simulating worker node failures. With heartbeat-based monitoring and automatic task re-queuing, all approaches achieved 100% task completion. Nonetheless, recovery delays of 60–80 units were observed, primarily due to detection latency before reallocation could be executed.
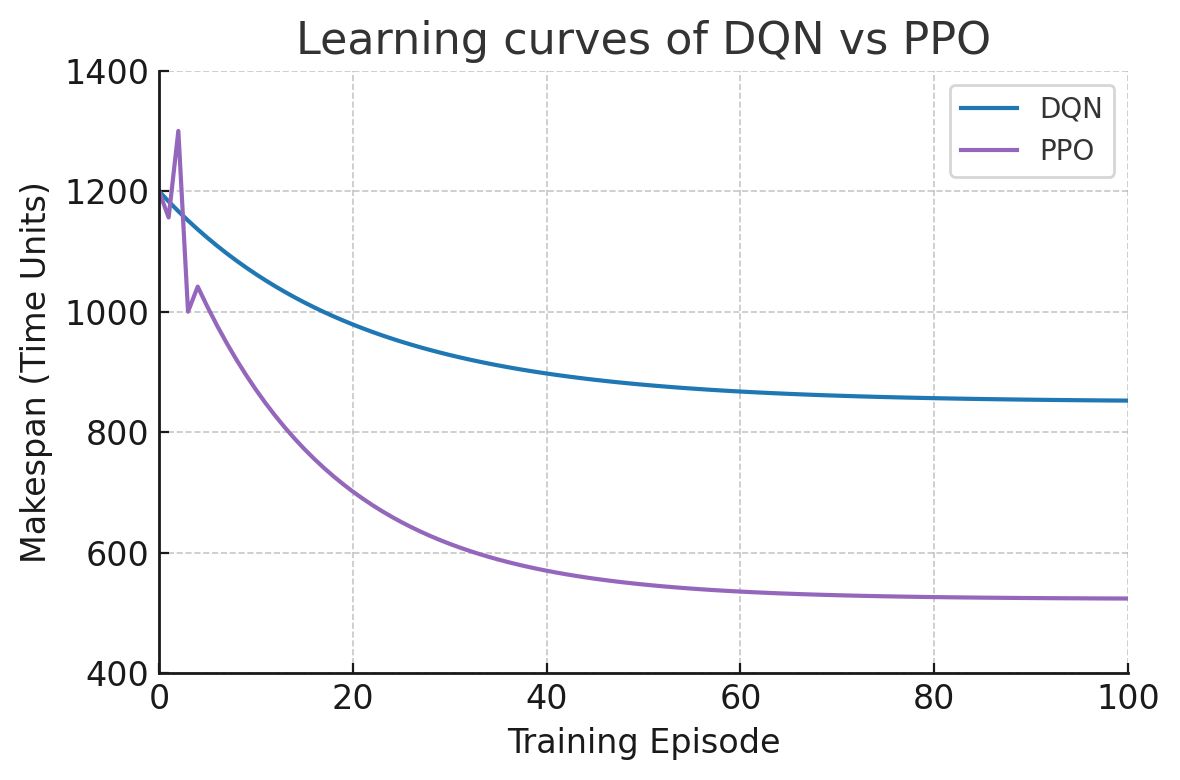
Figure 6: During the Training, RL Agents (PPO vs. DQN) Learning Curves, and Makespan (lower is better) Were Plotted as a vs Training Episode
In general, the error analysis highlights several key insights. First, reinforcement learning (RL) agents require sufficient training or pre-training phases to overcome their inherent early-stage instability. Second, the misclassifications observed in the Random Forest method underscore the importance of incorporating continuous learning mechanisms or fallback heuristic strategies to ensure reliability under unpredictable workloads. Third, the relatively high computational cost of NSGA-II may limit its applicability in real-time scenarios, despite its strong optimization capabilities.
On the other hand, the proposed architecture demonstrated robust handling of fault scenarios, with PPO in particular exhibiting more stable and resilient performance under failure conditions due to its balanced resource allocation strategy.
These findings emphasize the need for future work to explore more advanced exploration strategies for RL, develop online retraining techniques to maintain adaptability, and design hybrid approaches—such as combining fast ML-based decision-making with evolutionary re-optimization—to achieve superior results. Such directions not only address the observed limitations but also pave the way for more sustainable, intelligent, and resilient cloud infrastructures.
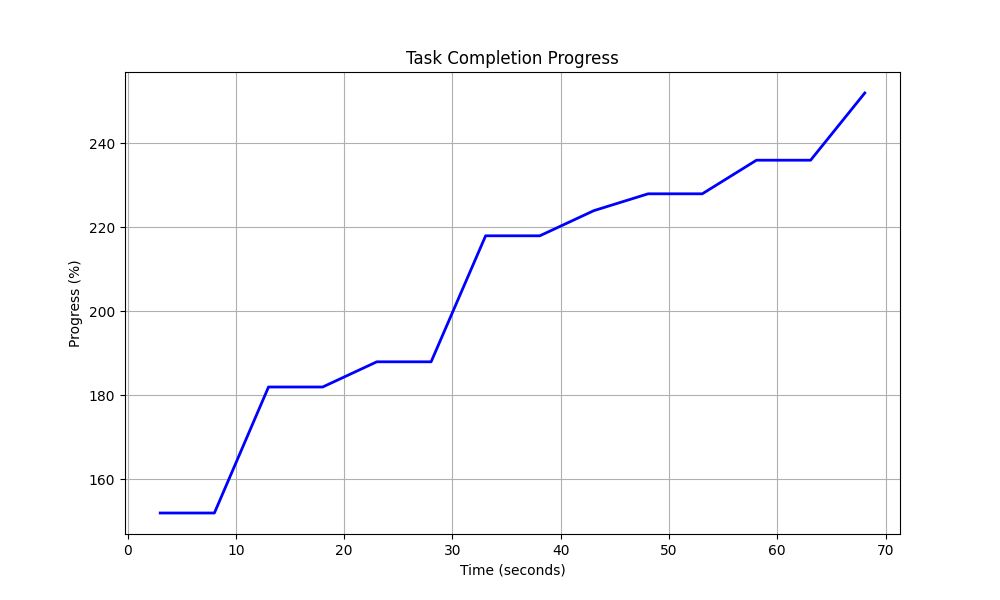
Figure 7: Task Completion Progress Over Time
4.4 Interpretability
In the adoption of ML-based methods for cloud management, performance alone is not sufficient; the interpretability of model decisions is equally critical. For operators, understanding why resource allocation decisions are made is indispensable for trust, debugging, and regulatory compliance. Therefore, the interpretability of the applied methods was assessed, and their applicability to automated cloud systems was discussed.
The results reveal marked differences among approaches. Random Forest produces relatively transparent and interpretable decisions, whereas deep reinforcement learning (Deep RL) agents remain comparatively opaque. NSGA-II provides valuable multi-objective trade-off insights but cannot be easily reduced to a simple decision logic. Thus, a trade-off between performance and interpretability emerges in production contexts. While PPO achieved the highest performance, it exhibited the lowest interpretability. Conversely, although Random Forest performed less effectively, it delivered far greater transparency.
Accordingly, depending on the application context, a “good but explainable” model may be preferable to an “excellent but opaque” one. As cloud systems advance toward greater autonomy, the development of trustworthy technologies—either by improving model explainability or through comprehensive testing and reliability analyses—becomes increasingly vital. Overall, the findings confirm the potential of ML to advance cloud resource management while also underscoring the necessity of explainability and interpretability techniques to foster user trust and ensure responsible integration.
5. Conclusion and Future Work
5.1 Summary of Contributions
This study provides a comprehensive investigation of ML-based approaches in cloud resource management, with a particular focus on dynamic allocation. Its primary contribution is the design and implementation of an ML-driven framework capable of adapting cloud resources in real time to workload demands. Unlike traditional static strategies, the proposed framework leverages predictive analytics and reinforcement learning to dynamically scale resources, thereby achieving substantial improvements in utilization, response time, reliability, and energy efficiency.
5.2 Limitations
Despite promising results, several limitations remain. Reinforcement learning demonstrated instability during the early training phase and required extensive hyperparameter tuning. The evaluation was conducted solely in a simulated environment, and has yet to be validated in real-world cloud deployments. Furthermore, energy consumption was not directly optimized as a primary objective, and interpretability remained constrained—particularly for deep RL models. Finally, the framework was tested on specific workload scenarios; extending its applicability to diverse applications, edge computing, or multi-cloud environments requires additional exploration.
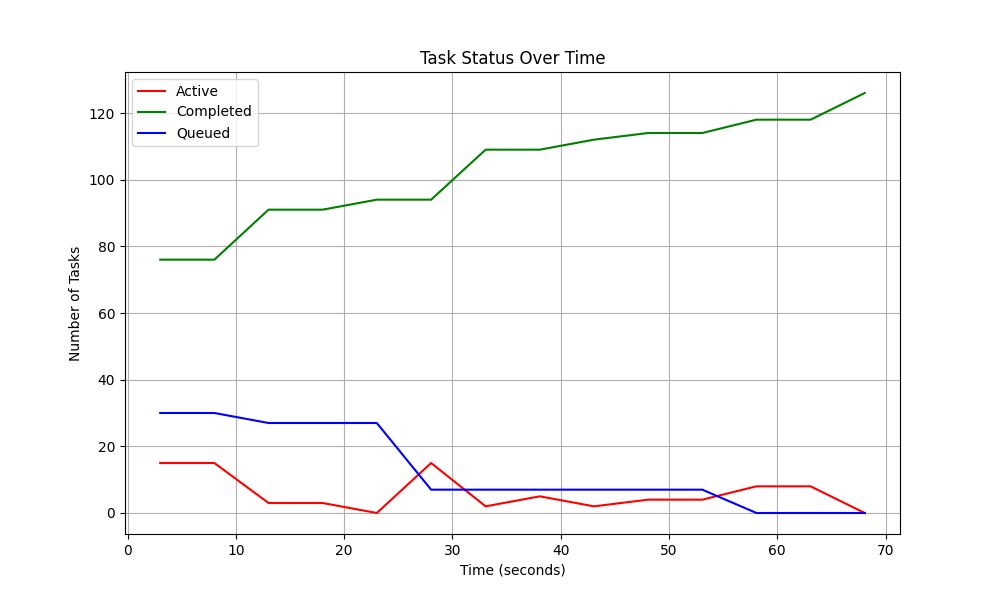
Figure 8: Task Status Over Time Showing the Number of Active, Completed, and Queued Tasks Results
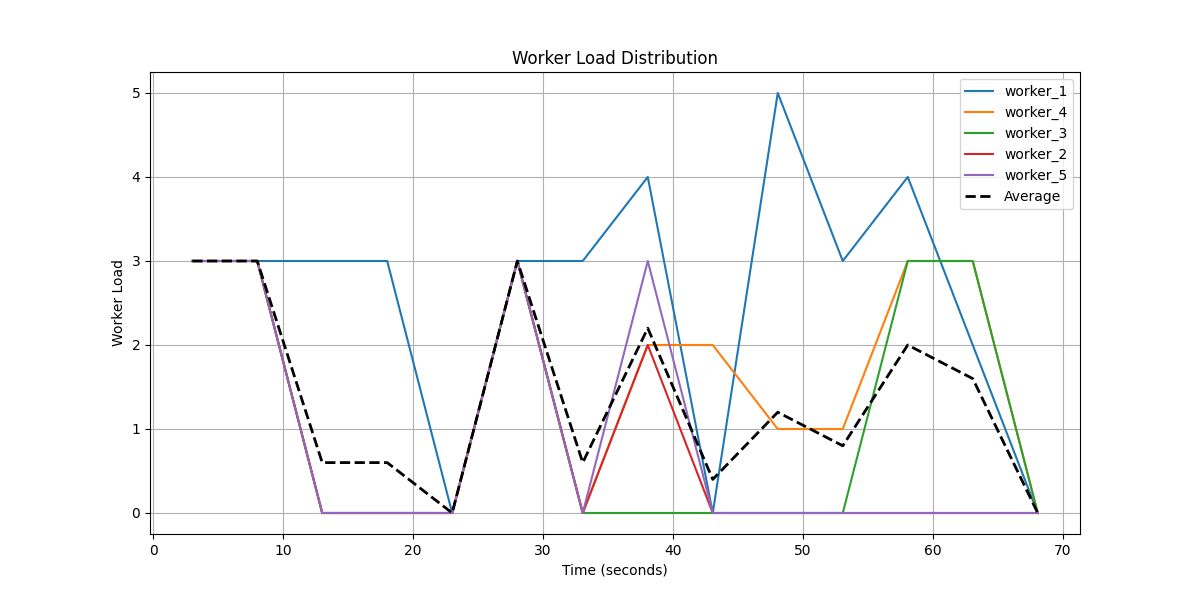
Figure 9: Worker Load Distribution Over Time Results
5.3 Future Research Directions
Future work should focus on improving the stability and sample efficiency of reinforcement learning (RL) agents through techniques such as reward shaping, transfer learning, and safe RL. Applying the proposed framework in real cloud environments is also critical to validate its scalability and resilience under practical conditions. Moreover, the integration of energy-aware decision mechanisms can directly contribute to sustainability goals by reducing the carbon footprint of cloud operations. Enhancing interpretability remains another important avenue; explainable AI (XAI) methods and advanced visualization tools may foster transparency and trust in automated systems. At a more advanced level, federated learning and multi-agent RL can be employed to design distributed, privacy-preserving, and highly scalable solutions for next-generation cloud infrastructures.
5.4 Concluding Remarks
The results demonstrate that ML-based dynamic resource allocation can significantly enhance efficiency, flexibility, and reliability in cloud management. Compared to static strategies, the proposed framework offers a more intelligent and scalable solution, emerging as a strong alternative for modern infrastructures. Future development and deployment of such methods in real-world systems will narrow the gap between academic innovation and industrial practice. Furthermore, as cloud ecosystems converge with 5G/6G autonomous networks, the proposed approach is expected to become a critical enabler for real-time optimization and quality-of-service enhancement, thereby advancing the vision of intelligent, sustainable, and resilient digital infrastructures.
References
Ahmad, M. A., Baryannis, G., & Hill, R. (2024). Defining complex adaptive systems: An algorithmic approach. Systems, 12(2), 45. https://doi.org/10.3390/systems12020045
Armbrust, M., Fox, A., Griffith, R., Joseph, A. D., Katz, R. H., Konwinski, A., ... & Zaharia, M. (2010). A view of cloud computing. Communications of the ACM, 53(4), 50–58. https://doi.org/10.1145/1721654.1721672
Beloglazov, A., & Buyya, R. (2012). Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of VMs in cloud data centers. Concurrency and Computation: Practice and Experience, 24(13), 1397–1420. https://doi.org/10.1002/cpe.1867
Buyya, R., Broberg, J., & Goscinski, A. M. (Eds.). (2011). Cloud computing: Principles and paradigms. John Wiley & Sons.
Calheiros, R. N., Ranjan, R., Beloglazov, A., De Rose, C. A. F., & Buyya, R. (2011). CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Software: Practice and Experience, 41(1), 23–50. https://doi.org/10.1002/spe.995
Gartner. (2023). Forecast analysis: Public cloud services, worldwide, 2021–2026. https://www.gartner.com
Lorido-Botran, T., Miguel-Alonso, J., & Lozano, J. A. (2014). A review of auto-scaling techniques for elastic applications in cloud environments. Journal of Grid Computing, 12(4), 559–592. https://doi.org/10.1007/s10723-014-9314-7
Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, 30, 4765–4774. https://papers.nips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf
Mao, M., Li, J., & Humphrey, M. (2010). Cloud auto-scaling with deadline and budget constraints. In 2010 11th IEEE/ACM International Conference on Grid Computing (pp. 41–48). IEEE. https://doi.org/10.1109/GRID.2010.5697966
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., ... & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533. https://doi.org/10.1038/nature14236
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). "Why should I trust you?": Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 1135–1144). ACM. https://doi.org/10.1145/2939672.2939778
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. https://doi.org/10.48550/arXiv.1707.06347
Singh, A. N., & Prakash, S. (2015). Challenges and opportunities of resource allocation in cloud computing: A survey. In 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom) (pp. 2047–2051). IEEE.
Statista. (2023). Impact of cloud computing on IT costs and efficiency. https://www.statista.com
Zhang, Q., Cheng, L., & Boutaba, R. (2010). Cloud computing: State-of-the-art and research challenges. Journal of Internet Services and Applications, 1(1), 7–18. https://doi.org/10.1007/s13174-010-0007-6